
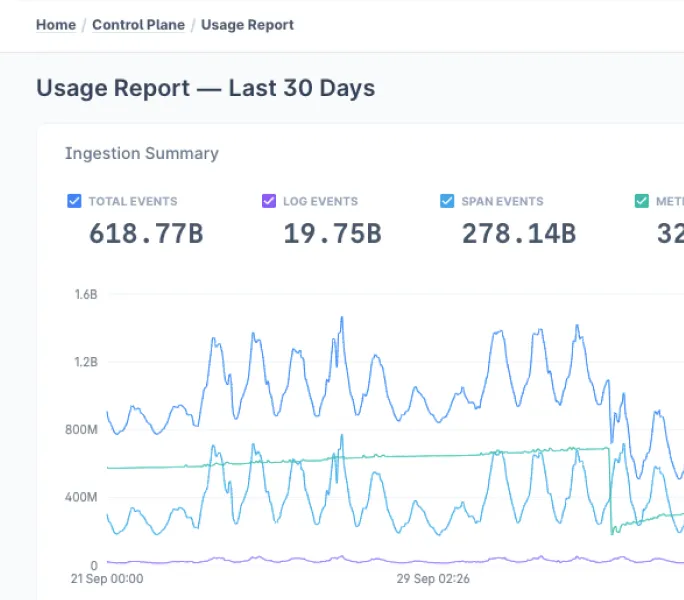
Last9 engineering

Extracting Account-Level CDN Metrics from Akamai Logs with Last9
Prathamesh Sonpatki, Aditya Godbole
Last9’s Single Pane for High Cardinality Observability
Sahil Khan

Think Data Warehouse, NOT Database.
Aniket Rao

What needs to change in software monitoring?
Aniket Rao

Back to the Future: The R-C-A of alerting
Aditya Godbole

Software Monitoring — Stuck in the 00s
Piyush Verma

Why your monitoring costs are high
Aniket Rao

The unresolved cost of High Cardinality
Prathamesh Sonpatki

Why you need a Time Series Data Warehouse
Rishi Agrawal
Real-Time Canary Deployment Tracking with Argo CD & Last9
Preeti Dewani
Monitor Google Cloud Functions using Pushgateway and Levitate
Aniket Rao

Golang Concurrency Masterclass by Swati Modi at Gophercon 2023
Last9

Do more with your metrics by Piyush Verma
Last9
Unwiring High Cardinality - SRE Day 2023
Last9

How to restart Kubernetes Pods with kubectl
Anjali Udasi

Levitate: Last9’s Managed TSDB Now on AWS Marketplace
Prathamesh Sonpatki

PromQL Macros in Levitate
Prathamesh Sonpatki

GCP Managed Service For Prometheus vs. Levitate
Prathamesh Sonpatki
A case for Observability outside engineering teams
Aniket Rao
Understanding the Rasmussen model for failures
Nishant Modak

How we tame High Cardinality by Sharding a stream
Piyush Verma

1979, a nuclear accident and SRE
Aniket Rao

How we tame high cardinality in time series databases
Piyush Verma, Swati Modi

What Site Reliability Engineering Needs: A Swarm of Bees
Aniket Rao

Take back control of your Monitoring
Nishant Modak

Observability is a practice, not a job
Aniket Rao

Using a Golang package in Python using Gopy
Arjun Mahishi

Who should define Reliability — Engineering, or Product?
Piyush Verma

Observability—OSS vs Paid vs Managed OSS
Satyajeet Jadhav

Learnings integrating jmxtrans
Saurabh Hirani

The neglected tech arctic winter — Internal SaaS expenses
Nishant Modak

Understanding “Cricket Scale”
Aniket Rao

What is MTBI?
Last9
Rethinking Anomaly Detection: Focus on business outcomes
Sanjay Singh
Observability is dead, long live observability
Aniket Rao
Self-managed Prometheus vs Managed Prometheus
Last9
The importance of structured communication in the world of SRE
Saurabh Hirani
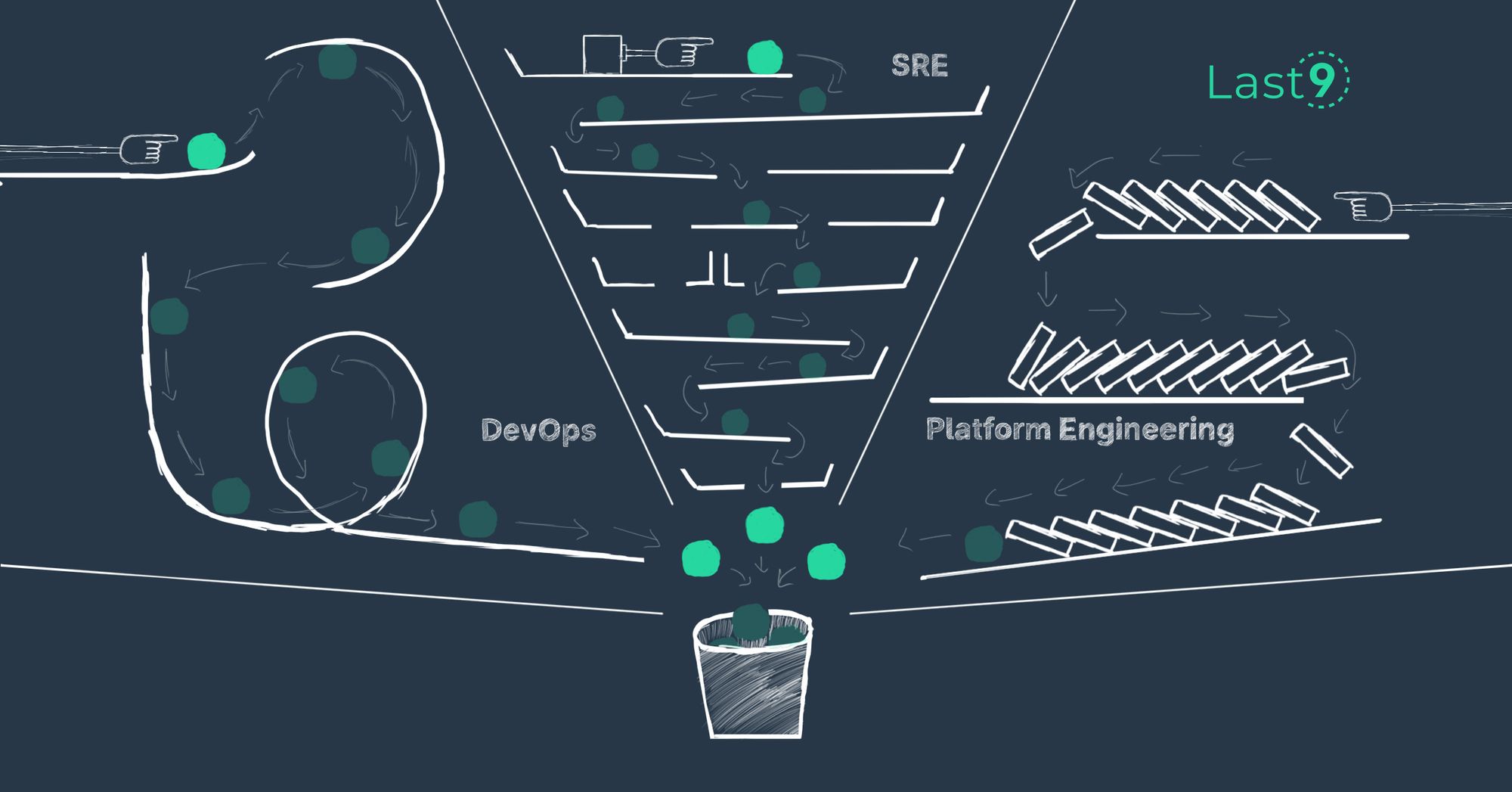
The difference between DevOps, SRE, and Platform Engineering
Prathamesh Sonpatki
Golang's Stringer tool
Arjun Mahishi
How to improve Prometheus remote write performance at scale
Saurabh Hirani
India vs Pakistan: SRE and the Shannon Limit
Satyajeet Jadhav
Battling Alert Fatigue
Last9
SLOs, SLIs, and SLAs: Understanding Key Service Metrics
Last9

Kubernetes Monitoring with Prometheus and Grafana
Last9
Why We Auto-Delete Slack Messages at Last9
Nishant Modak

Static Threshold vs. Dynamic Threshold Alerting
Last9

How we won Dukaan over
Aniket Rao
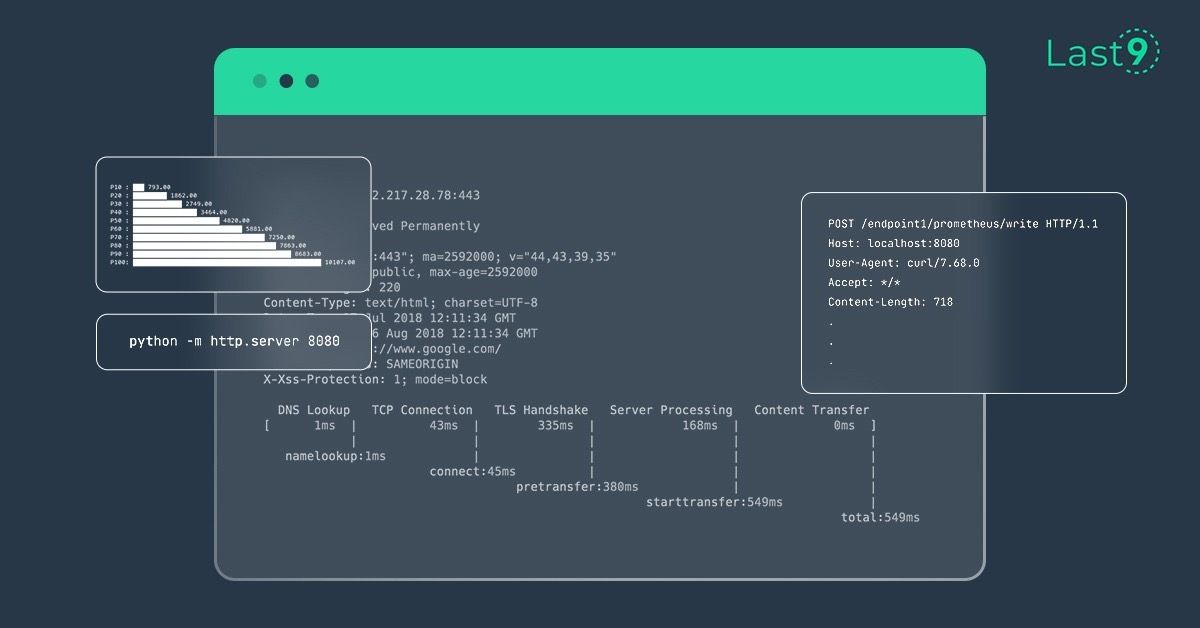
How to calculate HTTP content-length metrics on cli
Saurabh Hirani

Choosing Effective SLIs
Akshay Chugh

Running a Database on EC2 is Slowing It Down
Jayesh Bapu Ahire, Akshay Chugh

Doing SRE the Right Way!
Piyush Verma

Microservices - Tracking Dependencies
Akshay Chugh, Jayesh Bapu Ahire

SLOs eased
Piyush Verma, Saurabh Hirani

Rescuing a SPAghetti React project
Prathamesh Sonpatki

One year at Last9
Prathamesh Sonpatki